Eliminate Risk of Failure with Microsoft DP-203 Exam Dumps
Schedule your time wisely to provide yourself sufficient time each day to prepare for the Microsoft DP-203 exam. Make time each day to study in a quiet place, as you'll need to thoroughly cover the material for the Data Engineering on Microsoft Azure exam. Our actual Azure Data Engineer Associate exam dumps help you in your preparation. Prepare for the Microsoft DP-203 exam with our DP-203 dumps every day if you want to succeed on your first try.
All Study Materials
Instant Downloads
24/7 costomer support
Satisfaction Guaranteed
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named SQLPool1.
SQLPool1 is currently paused.
You need to restore the current state of SQLPool1 to a new SQL pool.
What should you do first?
See the explanation below.
You have an Azure Data Factory pipeline named pipeline1 that is invoked by a tumbling window trigger named Trigger1. Trigger1 has a recurrence of 60 minutes.
You need to ensure that pipeline1 will execute only if the previous execution completes successfully.
How should you configure the self-dependency for Trigger1?
See the explanation below.
Tumbling window self-dependency properties
In scenarios where the trigger shouldn't proceed to the next window until the preceding window is successfully completed, build a self-dependency. A self-dependency trigger that's dependent on the success of earlier runs of itself within the preceding hour will have the properties indicated in the following code.
Example code:
'name': 'DemoSelfDependency',
'properties': {
'runtimeState': 'Started',
'pipeline': {
'pipelineReference': {
'referenceName': 'Demo',
'type': 'PipelineReference'
}
},
'type': 'TumblingWindowTrigger',
'typeProperties': {
'frequency': 'Hour',
'interval': 1,
'startTime': '2018-10-04T00:00:00Z',
'delay': '00:01:00',
'maxConcurrency': 50,
'retryPolicy': {
'intervalInSeconds': 30
},
'dependsOn': [
{
'type': 'SelfDependencyTumblingWindowTriggerReference',
'size': '01:00:00',
'offset': '-01:00:00'
}
]
}
}
}
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 receives new data once every 24 hours.
You have the following function.
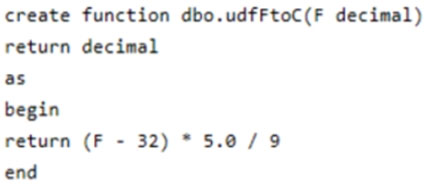
You have the following query.

The query is executed once every 15 minutes and the @parameter value is set to the current date.
You need to minimize the time it takes for the query to return results.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
See the explanation below.
You are creating an Apache Spark job in Azure Databricks that will ingest JSON-formatted data.
You need to convert a nested JSON string into a DataFrame that will contain multiple rows.
Which Spark SQL function should you use?
See the explanation below.
Convert nested JSON to a flattened DataFrame
You can to flatten nested JSON, using only $'column.*' and explode methods.
Note: Extract and flatten
Use $'column.*' and explode methods to flatten the struct and array types before displaying the flattened DataFrame.
Scala
display(DF.select($'id' as 'main_id',$'name',$'batters',$'ppu',explode($'topping')) // Exploding the topping column using explode as it is an array type
.withColumn('topping_id',$'col.id') // Extracting topping_id from col using DOT form
.withColumn('topping_type',$'col.type') // Extracting topping_tytpe from col using DOT form
.drop($'col')
.select($'*',$'batters.*') // Flattened the struct type batters tto array type which is batter
.drop($'batters')
.select($'*',explode($'batter'))
.drop($'batter')
.withColumn('batter_id',$'col.id') // Extracting batter_id from col using DOT form
.withColumn('battter_type',$'col.type') // Extracting battter_type from col using DOT form
.drop($'col')
)
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. Table1 contains the following:
One billion rows
A clustered columnstore index
A hash-distributed column named Product Key
A column named Sales Date that is of the date data type and cannot be null
Thirty million rows will be added to Table1 each month.
You need to partition Table1 based on the Sales Date column. The solution must optimize query performance and data loading.
How often should you create a partition?
See the explanation below.
Need a minimum 1 million rows per distribution. Each table is 60 distributions. 30 millions rows is added each month. Need 2 months to get a minimum of 1 million rows per distribution in a new partition.
Note: When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributions.
Any partitioning added to a table is in addition to the distributions created behind the scenes. Using this example, if the sales fact table contained 36 monthly partitions, and given that a dedicated SQL pool has 60 distributions, then the sales fact table should contain 60 million rows per month, or 2.1 billion rows when all months are populated. If a table contains fewer than the recommended minimum number of rows per partition, consider using fewer partitions in order to increase the number of rows per partition.
Are You Looking for More Updated and Actual Microsoft DP-203 Exam Questions?
If you want a more premium set of actual Microsoft DP-203 Exam Questions then you can get them at the most affordable price. Premium Azure Data Engineer Associate exam questions are based on the official syllabus of the Microsoft DP-203 exam. They also have a high probability of coming up in the actual Data Engineering on Microsoft Azure exam.
You will also get free updates for 90 days with our premium Microsoft DP-203 exam. If there is a change in the syllabus of Microsoft DP-203 exam our subject matter experts always update it accordingly.