- Home /
- Databricks /
- Data Engineer Professional /
- Databricks-Certified-Professional-Data-Engineer PDF
Databricks-Certified-Professional-Data-Engineer PDF Exam Questions:
How to Get Success in Databricks-Certified-Professional-Data-Engineer Exam:
- Avoid deceptive Databricks-Certified-Professional-Data-Engineer PDF Exam Questions.
- Focus on Databricks-Certified-Professional-Data-Engineer Questions (PDF) based on the latest exam syllabus.
- Make notes of Databricks-Certified-Professional-Data-Engineer PDF for better learning.
- Prepare from our latest Databricks-Certified-Professional-Data-Engineer PDF file and get success in first attempt.


Prepare Databricks-Certified-Professional-Data-Engineer Exam Within Short Time
Your knowledge and abilities are validated by passing the Databricks-Certified-Professional-Data-Engineer exam. Our PDF questions and answers will help you prepare for the Databricks-Certified-Professional-Data-Engineer exam in a short time because it includes questions similar to the real Databricks exam questions. After downloading the Databricks-Certified-Professional-Data-Engineer Databricks PDF exam questions, relevant to the actual exam, you can take a print of all questions and prepare them anytime, anywhere.
Realistic Scenario Based Databricks Databricks-Certified-Professional-Data-Engineer PDF Exam Questions:
Everyone wants to become certified Data Engineer Professional and improve his/her resume. You should practice with real Databricks-Certified-Professional-Data-Engineer questions. Students can benefit from the Databricks-Certified-Professional-Data-Engineer exam questions which are available in PDF format. The Databricks-Certified-Professional-Data-Engineer exam questions and answers are designed to match the criteria of the actual exam. If you use scenario-based Databricks-Certified-Professional-Data-Engineer questions you will have an extra potential to clear the exam on the first attempt.
An upstream system has been configured to pass the date for a given batch of data to the Databricks Jobs API as a parameter. The notebook to be scheduled will use this parameter to load data with the following code:
df = spark.read.format("parquet").load(f"/mnt/source/(date)")
Which code block should be used to create the date Python variable used in the above code block?
See the explanation below.
The code block that should be used to create the date Python variable used in the above code block is:
dbutils.widgets.text(''date'', ''null'') date = dbutils.widgets.get(''date'')
The other options are not correct, because:
The Databricks workspace administrator has configured interactive clusters for each of the data engineering groups. To control costs, clusters are set to terminate after 30 minutes of inactivity. Each user should be able to execute workloads against their assigned clusters at any time of the day.
Assuming users have been added to a workspace but not granted any permissions, which of the following describes the minimal permissions a user would need to start and attach to an already configured cluster.
When scheduling Structured Streaming jobs for production, which configuration automatically recovers from query failures and keeps costs low?
See the explanation below.
The configuration that automatically recovers from query failures and keeps costs low is to use a new job cluster, set retries to unlimited, and set maximum concurrent runs to 1. This configuration has the following advantages:
Therefore, this configuration is the best practice for scheduling Structured Streaming jobs for production, as it ensures that the job is resilient, efficient, and consistent.
The data engineering team has configured a Databricks SQL query and alert to monitor the values in a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
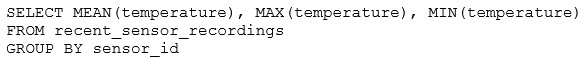
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120. Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
See the explanation below.
This is the correct answer because the query is using a GROUP BY clause on the sensor_id column, which means it will calculate the mean temperature for each sensor separately. The alert will trigger when the mean temperature for any sensor is greater than 120, which means at least one sensor had an average temperature above 120 for three consecutive minutes. The alert will stop when the mean temperature for all sensors drops below 120. Verified Reference: [Databricks Certified Data Engineer Professional], under ''SQL Analytics'' section; Databricks Documentation, under ''Alerts'' section.
A junior developer complains that the code in their notebook isn't producing the correct results in the development environment. A shared screenshot reveals that while they're using a notebook versioned with Databricks Repos, they're using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
See the explanation below.
This is the correct answer because it will allow the developer to update their local repository with the latest changes from the remote repository and switch to the desired branch. Pulling changes will not affect the current branch or create any conflicts, as it will only fetch the changes and not merge them. Selecting the dev-2.3.9 branch from the dropdown will checkout that branch and display its contents in the notebook. Verified Reference: [Databricks Certified Data Engineer Professional], under ''Databricks Tooling'' section; Databricks Documentation, under ''Pull changes from a remote repository'' section.
Reliable Source Of Preparation For Databricks Certified Data Engineer Professional Exam.
We provide Data Engineer Professional certification questions along with answers to assist students in passing the Databricks Exam. You can enhance your Databricks-Certified-Professional-Data-Engineer preparation with the help of an online practice engine. Try out our Databricks-Certified-Professional-Data-Engineer questions because 98% of Examskit users passed the final Databricks-Certified-Professional-Data-Engineer exam in one go.